

Unser Ziel: Erstklassige Analysen, um Rentabilität zu steigern und Einhaltung gesetzlicher Vorschriften zu gewährleisten
Durch unsere Risikoberatung wollen wir der Finanzdienstleistungsbranche Datenmanagement- und Datenanalysefähigkeiten zu vermitteln.
Unser erfahrenes Team von Risiko- und Data-Science-Spezialisten verfügt hier über praxiserprobtes state of the art Know-how.
Wir haben führende Kreditgeber in Österreich dabei unterstützt, die Rentabilität zu steigern, die Einhaltung gesetzlicher Vorschriften zu gewährleisten oder die Art und Weise zu verbessern, in der sie Daten zur Entscheidungsfindung verwenden.
Mit unserem Know-how aus Daten und Analysen haben wir Modelle erstellt und Einblicke für große und kleine Unternehmen geliefert.
Unser kooperativer Ansatz stellt sicher, dass unsere Projekte einen echten Mehrwert für unsere Kunden liefern!
Wie sieht ein wartungsschonendes und dynamisches Ratingsystem aus?
Zu Beginn müssen die grundlegenden Ziele eines Ratingsystems abgeleitet werden. Wir haben in unserem Use Case die musst-haves der Banken gelistet:
Revisionssicher – da ein Ratingsystem regelmäßig von internen und externen Revisoren geprüft wirdWartungsarm – der Betrieb des Systems soll ressourcenschonend sein und wenig kostenVerwaltbar – das System ist Teil der Datenbankarchitektur, müssen alle Richtlinien der Data Governance (BCBS239) eingehalten werdenmandanten-tauglich – die Umsetzung sollte skalierbar sein, damit jeder Mandant seine eigene Konfiguration nutzen kann
Um diesen Anforderungen gerecht zu werden wird in vielen Systemenvarianten mit einem schichtgetriebenen (Layer-)Design gearbeitet. Dieses eignet sich auch zur Abbildung von Ratingsystemen, welche zur Bewertung von Kunden verwendet wird.
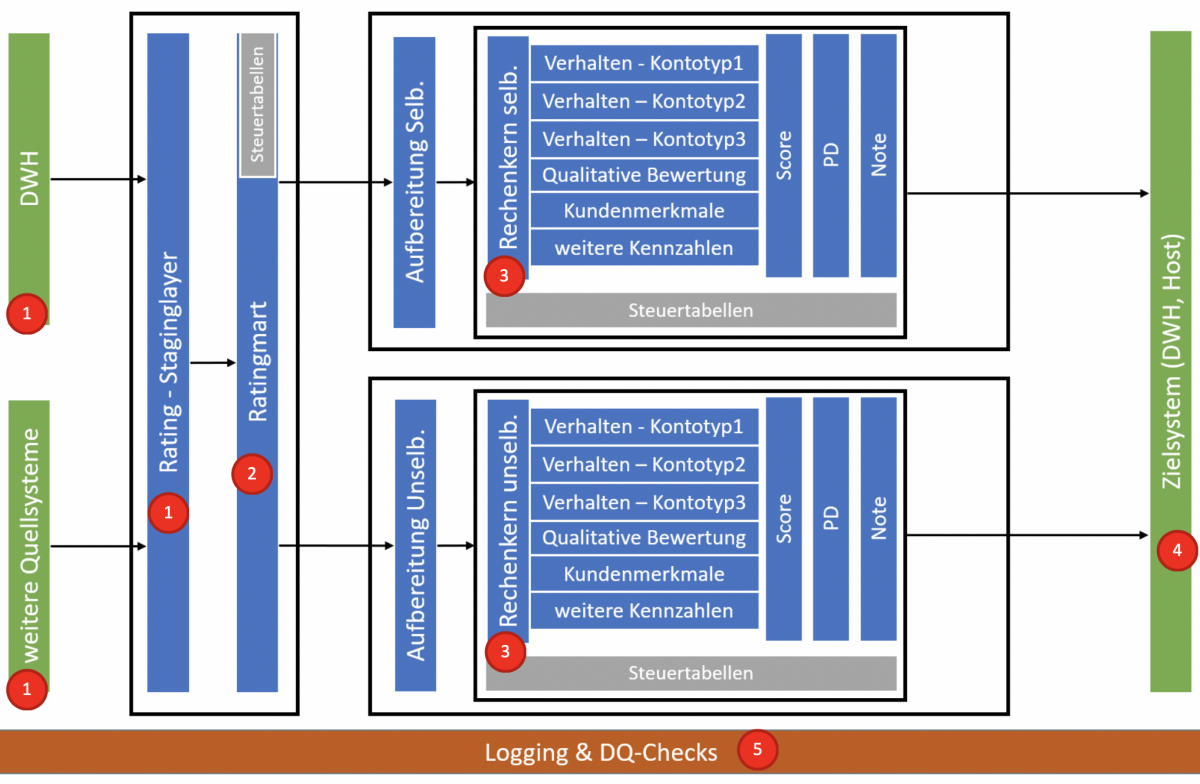
In einer idealen Welt gibt es ein vollständiges Data Warehouse aus dem alle relevanten Daten für den dispositiven Bereich bezogen werden können. In der Praxis erleben wir oft, dass es keinen zentralen Datenbestand gibt bzw. nicht alle Daten konsistent und vollständig enthalten sind, daher müssen alle weiteren notwendigen internen und externen Quellen und Systeme angebunden werden. Sind alle notwendigen Datenquellen bekannt, landen die Daten in einem Staging Layer, welcher nur zur Datensammlung dient. In diesem Schritt empfehlen wir noch keine Datentransformationen durchzuführen, da dieser Layer für Datenanalysen im Fehlerfall verwendet werden kann, so können sich Daten aus dem Vorsystem ändern und es wird dann sehr schwer manche Berechnungen nachzuvollziehen. Darüber hinaus werden mögliche operativen Quellsysteme nur einmal mit den Abfragen belastet.
Der Ratingmart dient zur Abbildung aller Daten, welche später im Rechenkernen verwendet werden. Hier sollte auch die gesamte Businesslogik abgebildet werden. Diese kann man grob in folgende Funktionsgruppen unterteilen:
Generelle TransformationenBerechnungen von KennzahlenAbleitungen von StammdatenZusammenführung von DatenMapping von Daten / Umschlüsseln
Auch die Tabellen bzw. die Datenbereiche sollen in Gruppen zusammengehalten werden, hier beispielsweise:
KundenstammdatenVerhaltensdatenFinanzdatenSteuertabellen
TIPPS:
>Funktionsgruppen (bsplw. Kennzahlen) und Daten (bsplw. Kundenstammdaten) sollten nach einer einheitlichen Namenskonvention benannt werden, da die Komplexität des Systems über die Lebensdauer erfahrungsgemäß stark zunimmt.
>Werden alle Berechnungen, Transformationen und Ableitungen im Ratingmart durchgeführt, kann es nicht dazu kommen, dass jeder Rechenkern die gleiche Operation(en) durchführen muss. Dies sollte als generelle Regel festgelegt werden.
>Jede Berechnung, die nicht direkt mit der logistischen Regression oder anderen statistischen Formeln zusammenhängt, muss im Ratingmart durchgeführt werden. Damit können alle Rechenkerne auf alle Kennzahlen zugreifen und Doppeltbelegungen von Namen bzw. Kennzahlen, welche unterschiedlich ermittelt werden, werden vermieden (wichtig für die Data Governance!).
>Alle Daten, die in einen Rechenkern verwendet werden, müssen über den Datamart kommen. Es führt (vermutlich) zu doppelter bzw. dreifacher Datenhaltung, aber dadurch hat man ganz klare Abhängigkeiten (alle Daten kommen immer aus der vorigen Schicht) und einheitliche Datenpunkte bei Systemabstürzen.
Nach dem Ratingmart folgen alle Rechenkerne (z.B. Rechenkern für Privat Selbständig, Privat Unselbständig, Konzern, KMUs etc.). Jeder Rechenkern besteht aus einer Bridge (eigentlich ein eigener Staging Layer) und dem Berechnungslayer. In die Bridge werden nur relevante Daten geladen, die für den jeweiligen Rechenkern relevant sind. Alle Tabellen, Spalten und Datensätze, die nicht benötigt werden, werden gefiltert.
Die Bridge scheint auf den ersten Blick unnötig, jedoch erfüllt sie folgende Funktionen:
>Komplizierte Berechnungen auf der Quelle für Rechenkerne blockieren nicht andere Rechenkerne
>Andere Kunden/Mandanten können auch den Rechenkern verwenden (falls die Daten aus komplett anderen Quellen verwendet werden). Diese Mandanten müssen dazu ihre Daten in die notwendige Struktur bringen und erstellen sich
adhoc einen eigenen Ratingmart
>Ablöse eines DWHs oder der Neubau eines Ratingmart kann unabhängig vom Rechenkern passieren
Performance ohne Kompromisse erzielt man im Rechenkern, wenn nur mehr die Berechnungen für das statistische Modell durchzuführen sind. Im Grunde genommen kann man auf folgende Logiken reduzieren:
>Haircutlogik / Winsorization
>Einzelscores
>Gesamtscore
>Ausfallswahrscheinlichkeit
>Berechnung der Ratingnote
Gestalten Sie Ihren Arbeitsalltag einfacher und effizienter und legen Sie alle Werte aus dem statistischen Modell in Steuertabellen ab. In jeder Steuertabelle sollten folgende Informationen enthalten sein:
>Mandant/Kunde: Jeder Mandant hat die Möglichkeit für eine eigene Steuerung
>Rating Version: Jede Neukalibrierung sollte als eigene Version abgelegt werden (Vergleiche und Simulationen werden damit ermöglicht)
>Gültig von / gültig bis: Falls sich Werte innerhalb der Ratingversion ändern sollten (z.B.: bei Fehlern bzw. kleinen Anpassungen)
Für eine nahtlose Integration mit den gängigen Datenhaltungssystemen und BI-Tools müssen die Ergebnisdaten in die Zielsysteme überführt werden und für Risikoberichte, die Bankapplikationen oder für den Endkunden in einem real time Prozess, aufbereitet werden. Nach der Berechnung sollten die Ergebnisse unbedingt historisiert werden. Aus unserer Sicht sind folgende Werte Daten hierbei besonders interessant:
>alle relevanten Input-Werte des Modells
>alle Ergebnisse bzw. Teilergebnisse
>Initial-Parameter, mit denen die Berechnungen gestartet wurden (zumindest: Mandant, Datum und Ratingmodellversion)
Wissend, dass wir hier das unendliche Thema Datenqualität nicht einmal in seinen Grunddimensionen streifen, ist es wichtig im Kontext eines Ratingsystems über alle Schichten hinweg ein einheitliches Logging herzustellen und Basisdatenchecks (Schwellwertprüfungen, Logik-Checks, etc) aufzusetzen. Jeder Berechnungslauf und die dazugehörenden Jobs müssen zumindest „ausreichend“ dokumentiert werden. Ein ausreichendes Logging ist für uns gegeben, wenn es für folgende Punkte sinnvoll abgedeckt werden:
>Programmabstürze
>Performanceprobleme und -monitoring
>Revisionsprüfungen und Data Governance (bsplw. auch BCBS239)
–
Author: Christoph Werlee, Senior Berater der data square und Experte für DWH/BI-Themen
–
Wenn Sie nach diesem Vorgeschmack mehr wissen wollen, freuen wir uns, wenn Sie uns kontaktieren!
Für weitere Informationen kontaktieren Sie uns unter office@datasquare.at